



Contents:
One of the biggest misconceptions about predictive analytics is that the hard part is building the model. By the time you open any machine learning platform, most of the important work should already be done.
A good model starts with good data, and that means spending time understanding the business problem before thinking about algorithms. Whether you’re trying to predict customer churn, loan defaults, equipment failures or claim outcomes, the preparation process is remarkably similar.
1. Start with the outcome, not the data
The first question should never be “What data do we have?”
It should be “What are we trying to predict?”
That sounds obvious, but it changes the entire project. A clearly defined target variable allows you to work backwards and identify which pieces of information are genuinely useful. Without that, it’s easy to collect dozens of fields that add complexity without improving the model.
Inside Panintelligence, we refer to this element as Objective, and its is, alongside the Identifier, a mandatory field.
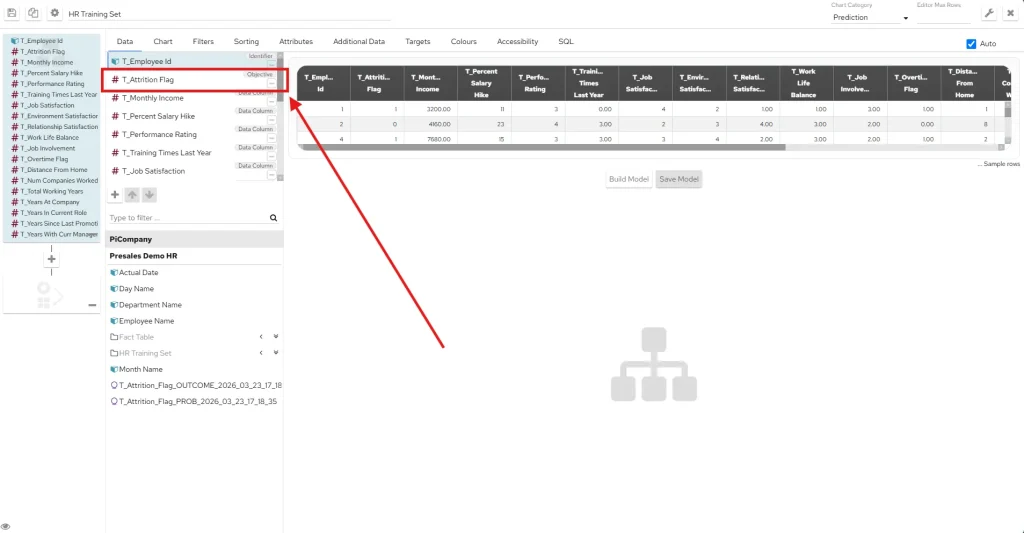
If you want to understand how our Analytics chart works, please visit our documentation.
What is piAnalytics? - pi Documentation - Confluence
2. Make sure you’re not giving the model the answer
One of the easiest mistakes to make is introducing data leakage.
Imagine you’re trying to predict whether a customer will default on a loan, but one of your features is “Default Date”. Your model will achieve incredible accuracy… because you’ve accidentally told it the answer.
A good rule of thumb is to ask yourself:
“Would this information have been available at the exact moment I wanted to make the prediction?”
If the answer is no, it doesn’t belong in the model.
3. Engineer features that describe the problem
Raw data is rarely the most useful data.
Instead of simply providing “Account Created Date”, you might calculate “Customer Tenure”. Instead of storing every transaction individually, you might calculate the average spend over the last 30 days. These derived features often capture the behaviour you’re trying to model much better than the original fields.
Feature engineering isn’t about creating more columns. It’s about creating more meaningful ones.
Inside Panintelligence, you can prepare your data using SQL inside a data object.
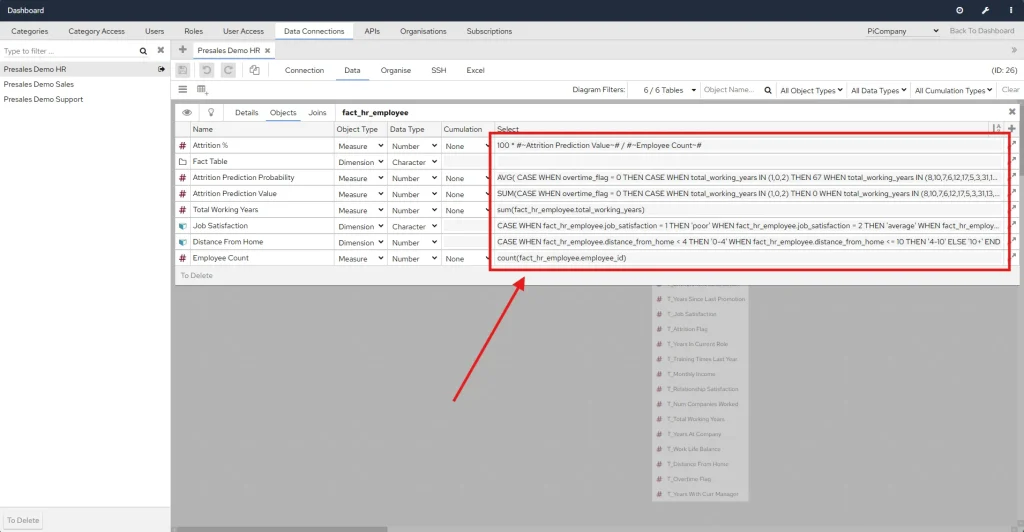
You can find more on Data Object in our documentation.
Object Configuration - pi Documentation - Confluence
4. Don’t ignore missing data
Missing values are telling you something.
Sometimes they indicate poor data quality. Sometimes they represent a genuine business process. A missing field might mean a customer skipped a form, never used a feature, or simply didn’t need to provide that information.
Before replacing null values, spend a little time understanding why they’re missing. That context can be just as valuable as the data itself.
5. Think about explainability from day one
The final step has nothing to do with accuracy.
If your users can’t understand why the model reached a particular prediction, they’ll struggle to trust it. Explainability isn’t something you add at the end of a project—it should influence how you prepare your data, select your features, and choose your modelling approach.
Simple, well-understood features often produce models that are easier to explain, maintain and improve over time.
Final Thoughts
Predictive analytics is often presented as an AI problem, but in practice it’s a data preparation problem. The quality of your features, the clarity of your target, and the integrity of your dataset will usually have a much greater impact on the final result than the choice of algorithm.
Getting the data right isn’t the exciting part of the project, but it’s almost always the part that determines whether the model becomes useful or simply another experiment.






